
Misclassification of Sex in Central Cancer Registries
Recinda L. Sherman, MPH, PhD, CTR; Francis P. Boscoe, PhD; David K. O’Brien, PhD, GISP; Justin T. George, MPH; Kevin A. Henry, PhD; Laura E. Soloway, PhD; David J. Lee, PhD
Journal of Registry Management 2014 Volume 41 Number 3
Background
Cancer registries are big databases containing the medical information of cancer patients, and are an essential tool for following large cancer trends, such as are routinely reported in the press. When you hear that the rate of a particular cancer is increasing or declining it will be based on data from registries. When people quote the number of cases of a particular cancer a year, these are estimates based on rate information from cancer registries. Ultimately when we look at life expectancy questions, registry data can be a critical information source. In some European countries, particularly in Scandinavia, state-supported central registries cover the entire population, and are powerful resources for answering key questions. In the US and many other countries the registries may be regional or even hospital based, and as such are restricted in their usefulness or require significant maintenance and support.
A central axiom of any data base is, of course, garbage in – garbage out. The soundness of the data is fundamental to its value, and often data integrity and accuracy are where most of the resources go in a well maintained registry. One important source of error is data entry – human error, when filling out paper or electronic forms.
Another truth is that when you are dealing with large numbers of records, even small error rates can have an impact, particularly on rare cancers. The error rate of miscoding sex is low – perhaps around 1 in 200-500 – but when you have hundreds of thousands of records, a you’ll have a few. It turns out that for cancer registries, one tool that has been used to clean this up is what is called ‘site-sex’ edits: if the cancer diagnosis is ovarian, the sex must be female. If prostate, then male.
But what about cancers that are not sex-specific? If the sex distribution is about even then the errors are likely to cancel each other out. But what about cancers like breast, where the sex-ratio is very uneven? Here even a low rate of females misclassified as males could artificially increase the number of males. In the US we estimate about 232,670 new cases of female breast cancer a year, and about 2,200 male. It is easy to see that if 0.1% of the female cases were misclassified as male, this would look like a 10% increase in incidence of the male disease – potentially alarming. Of course for breast the ‘site-sex’ edit cannot be done. So what is the solution?
Findings
Sherman and colleagues explored the use of a ‘name-site’ approach, meaning that they used first names and cancer site. As they discuss in their paper, not all names are useful for this. There are some that are highly gender specific, and have been for many years (e.g. Elizabeth and Charles). Then there are others that are inherently ambiguous (e.g. Leslie), or are different in different cultures (e.g. Andrea, Angel, Carmen and Jean which are common for females in much of the US, but are male names among Hispanics, Haitians and Italians). Lastly there are even names that the authors point out have changes in sex-association, such as Rosario which was typically male in 1900 but typically female in 1940. With great care, then, these issues can be incorporated and give you a chance to look at the problem.
Sherman et al made two main findings. The first is perhaps best illustrated by the case of the Florida registry they examine, and where they do a quality project:
“The first name of male breast cancer patients diagnosed from 1981-2000 were visually reviewed. A total of 904 of approximately 3,800 male cases of breast cancer were identified as potentially female based on first name. All but 3 were confirmed female by the hospitals, and the sex code was corrected in the registry data.”
Wow – nearly a third of the male breast cancer cases in this data set were actually female! Here’s what it looks like graphically:
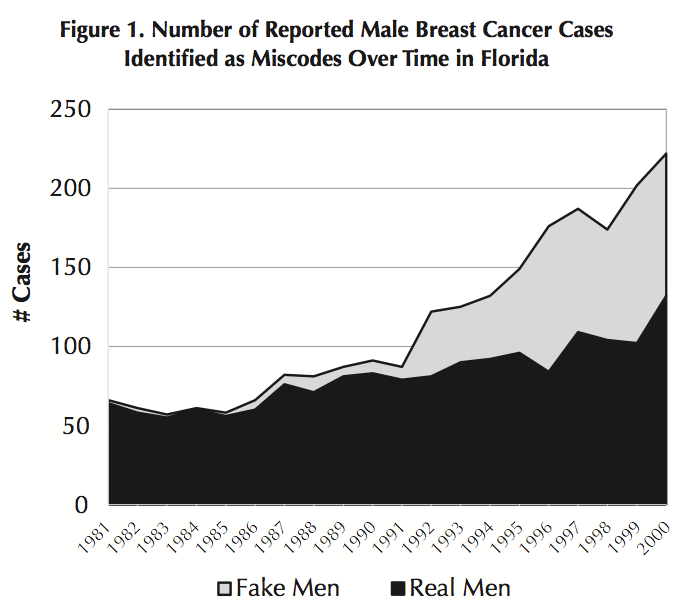
So instead of an apparent alarming increase in male breast cancer, they found that this was due to infrequent misclassifications of women with breast cancer as men.
Now this Florida work was done manually – quite an undertaking, even with only around 1,000 cases. How about the more ‘name-site’ sex edit? Well, it correctly identified 729 of the “fake men” as female, plus confirmed that one of the “real men” flagged as possible females, as actually a male. For the remainder the name was not gender specific. Encouragingly, the ‘name-site’ sex edit did not misclassify any males as females.
Comment
So why does all this matter? Well, with a rare cancer, you have few cases to base knowledge on, and so you are more vulnerable to data error: a handful of misclassified cases are not going to change the conclusions of a study with tens of thousands of cases, but might if you have less than a thousand. As the authors state:
“For […] sex-skewed sites, the sex ratio of cases identified as potential miscoded sex is exactly inversely proportional to the sex ratio of the cancers themselves.”
So this new edit strategy can be really helpful in eliminating women (or as the authors say, “fake men”) among the men (“real men”) and so avoid an overestimation of the incidence of male breast cancer, and also keeping the data on men ‘cleaner’, enhancing the opportunities to detect differences with women. After all, if a good number of the “men” in your study are actually women, and you find no difference between men and women, perhaps the two are connected.
However, its not all good. Here are the authors summarizing the down side:
“Focusing on improbable sex for male breast cancers only removes female cases miscoded as male, which falsely suppresses the rate because no misclassified female breast cancer cases are added back into the male category.”
In other words, there may very well be men hidden among the many female cases. Here of course the challenge is that with many female cases, a ‘name-site’ screen would identify many cases that could be misclassified, and this would require significantly more effort than the reverse. Given that the practice environment for breast cancer is built for women, I can’t help worrying that men are perhaps classified as women quite often. I have been asked at patient check in at our breast cancer center, when I was by myself, whether I was the patient. I doubt a woman gets asked that question. Of course missing the men misclassified as women could be serious. Here are Dr. Sherman and colleagues:
“However, if the registry only resolves breast cancers that are potentially miscoded as male but not the reverse […], the registry will be falsely suppressing male breast cancer rates.”
In short, we may not even really know how many men get breast cancer every year.
